
A practical guide to self-hosting LLMs on AWS
Introduction
The pace of progress in AI goes beyond the dominant API-driven services like OpenAI’s ChatGPT, Google’s Gemini, and Anthropic’s Claude. Open-source Large Language Models (LLMs) are emerging rapidly and offer compelling alternatives. In particular, Chinese AI firm DeepSeek is competing fiercely with leading proprietary API-driven solutions.
Open-source LLMs provide unparalleled flexibility and control compared to closed-box APIs.Thus, this dynamic landscape offers exciting opportunities across many sectors, especially EdTech. Which open-source LLM should we choose to deploy on our server? Of course, there is no single, unique answer to this question. The answer depends on our needs.
Now, we compare Llama 3.1, Gemma 3, Phi-4, Mistral-small 3.1, and DeepSeek R1 models using a dataset containing German and Dutch tasks. Also, we use older NVIDIA T4 GPUs (G4dn instances) from AWS and newer AI-optimized L4 GPUs (G6 instances). Let’s compare the speed, efficiency, and cost!
Table of Contents
Open-source LLMs in EdTech: Pros & Cons
Open-source Larger Language Models (LLMs) offer a path to powerful AI without the licensing fees and restrictions of proprietary models. Therefore, they strongly attract the Edtech sector. However, adoption requires careful consideration.
The Advantages (Pros):
-
- Significant cost savings (on licensing): Eliminates expensive licensing fees, lowering the barrier for startups and institutions.
- Unmatched customization & flexibility: Allows fine-tuning on specific curricula, pedagogies, reading levels, or languages to address diverse educational needs.
- Enhanced data privacy & security control: Self-hosting on your AWS infrastructure keeps sensitive student data in-house, aiding compliance (GDPR, COPPA).
- Transparency & auditability: Open access allows understanding model workings, identifying biases, and building trust.
- Community support & rapid innovation: Leverages global open-source collaboration, speeds up iteration, and preserves independence from proprietary platforms.
The disadvantages (cons) & challenges:
-
- Infrastructure & operational costs: While the software is free, running it isn’t. LLMs demand powerful GPUs (like AWS G6 instances), memory, and storage. These infrastructure, maintenance, and energy costs are significant.
- Requirement for technical expertise: Deploying, fine-tuning, and managing open-source LLMs requires skilled MLOps, data science, and infrastructure teams.
- Performance variability & quality control: Performance can vary, and ensuring accuracy while minimizing “hallucinations” needs rigorous testing and monitoring.
- Security & safety burden: Responsibility for patching vulnerabilities and implementing robust safety guardrails falls entirely on your team.
- Support limitations: Community support lacks the guaranteed response times of commercial vendors.
- Potential for inherited bias: Requires careful evaluation and fine-tuning to mitigate biases in training data.
In essence, open-source LLMs offer incredible potential but demand a clear understanding of the technical and resource commitments.Our performance data, including benchmarks, plays a key role in assessing whether the benefits justify the challenges.
AWS benchmark on models, instances & metrics
We compared several popular open-source LLMs across various AWS configurations to offer actionable insights.
Models tested:
-
- deepseek-r1: (DeepSeek AI, 14B)
- gemma3: (Google, 27B)
- llama3.1 (Meta, 8B version)
- mistral-small3.1 (Mistral AI, ~24B)
- phi4 (Microsoft, ~14B)
AWS instances used:
We compared GPU generations to highlight performance differences:
-
- G4dn Instances (g4dn.4xlarge, g4dn.12xlarge): Utilize previous-generation NVIDIA T4 GPUs.
- G6 Instances (g6.2xlarge, g6.4xlarge, g6.12xlarge): Feature newer NVIDIA L4 GPUs. According to AWS, these instances offer significantly improved performance and cost-efficiency for deep learning inference compared to G4dn instances. Our results also validate this claim.
Metrics measured:
-
- Latency (avg_resp_time): Total time (seconds) for a complete response. Lower is better for interactivity.
- Throughput (avg_token_per_sec): Text generation speed (tokens/second). Higher is better for content generation.
- Cost (instance price (monthly)): Estimated 24/7 monthly instance cost.
- Task success (g6.2xlarge only): Success rate (%) on specific Dutch (NL) and German (DE) tasks, indicating real-world task effectiveness.
Performance deep dive: L4 Advantage, cost efficiency & task accuracy
Our benchmarks highlight distinct trade-offs between instance types.
1. The G6 (L4 GPU) advantage is clear:
Across the board, G6 instances with newer L4 GPUs consistently deliver better performance, lower latency, and higher throughput. This advantage remains, even when compared to G4dn instances of similar size or higher cost, which use older T4 GPUs.This confirms that for modern LLM inference workloads, G6 offers significantly better value and efficiency.
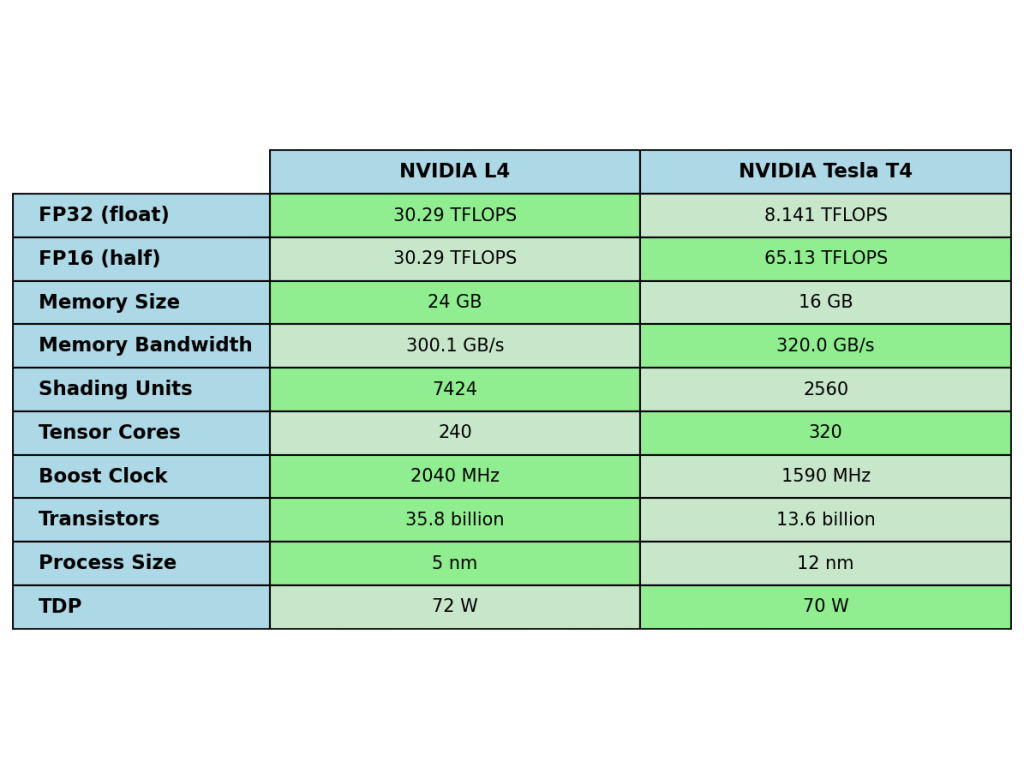
2. Latency insights (Response time):
-
- For real-time needs (AI tutors), llama3.1 and phi4 are fastest (often < 1 sec on G6).
- gemma3:27b offers reasonably fast responses on G6 (~1.2 sec).
- deepseek-r1:14b shows the highest latency (15-23 sec).
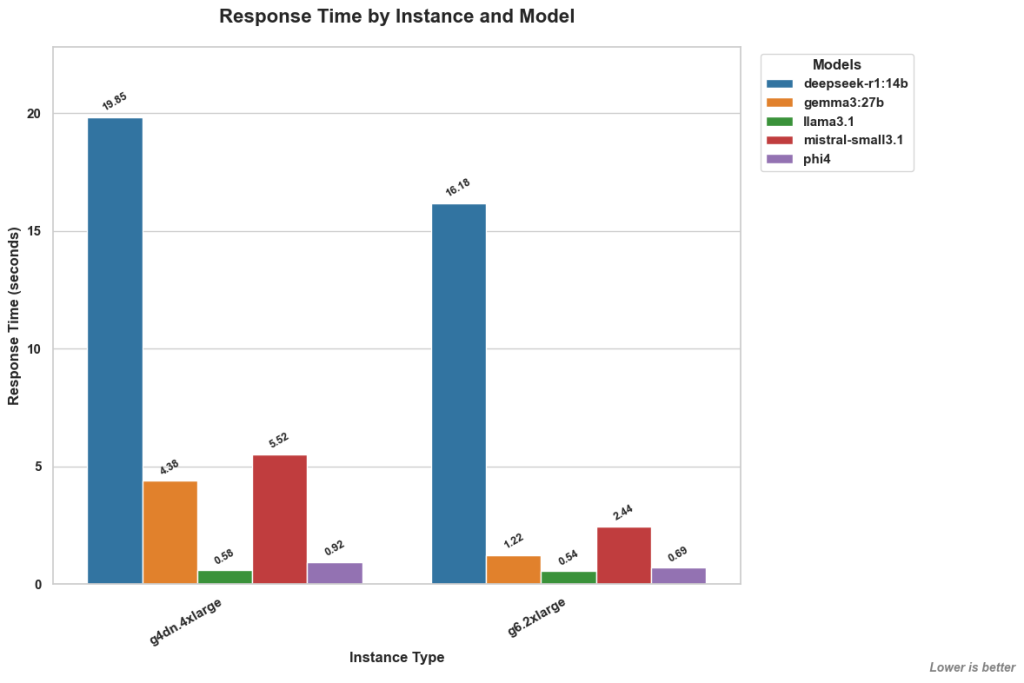
3. Throughput Insights (Generation speed):
-
- llama3.1 dominates throughput (> 40 tokens/sec on G6), ideal for rapid content generation.
- phi4 and deepseek-r1:14b (on G6) offer good throughput (~24 tokens/sec).
- gemma3:27b and mistral-small3.1 generally have lower throughput.
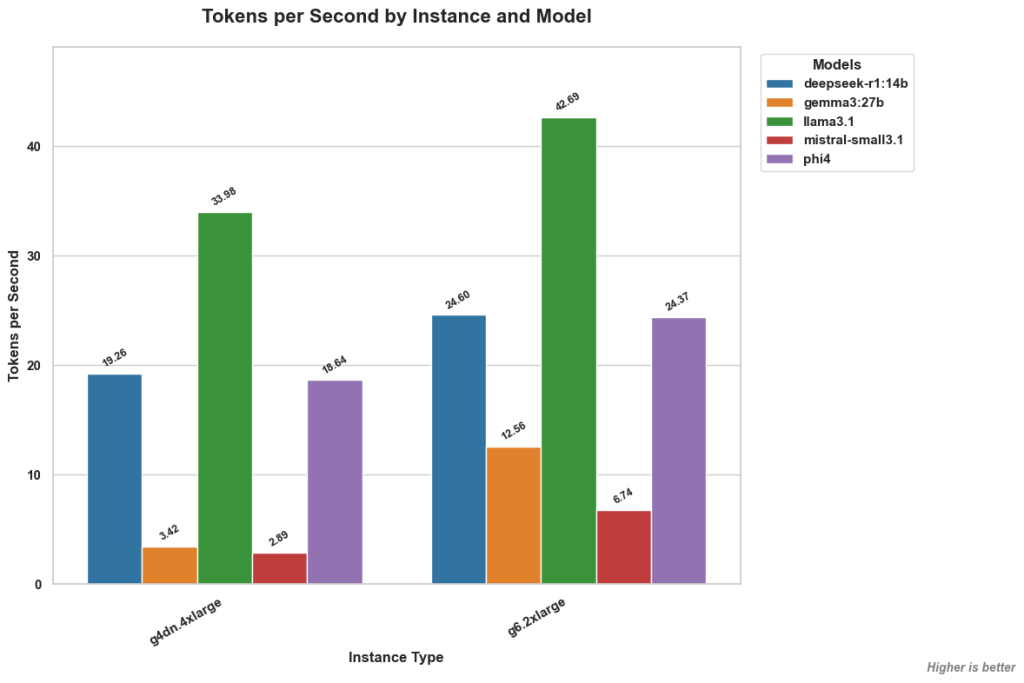
4. Cost efficiency & instance choice – Finding the Sweet Spot
-
- The g6.2xlarge: A cost-effective starting point
Among the G6 instances tested, g6.2xlarge stands out. It is the most affordable option (around $880/month), and delivers peak or near-peak performance for top models like LLaMA 3.1 and Phi 4.
This makes it ideal for EdTech teams that want to self-host open-source LLMs on AWS, similar to an on-premise setup but with the flexibility of the cloud. Because it combines strong performance with manageable costs, g6.2xlarge is a great starting point for teams focused on cost efficiency. - Scaling for Parallel Demand
While g6.2xlarge is efficient, upgrading to g6.4xlarge provides moderate performance gains. However, the larger g6.12xlarge—which costs about $4,143/month—only shows clear benefits for certain models, such as Mistral-small 3.1. Even so, larger instances like g6.4xlarge or g6.12xlarge become necessary when handling high volumes of concurrent user requests or resource-intensive models. So, it’s best to start small with g6.2xlarge, and scale up only if performance data under load justifies the extra cost.
- The g6.2xlarge: A cost-effective starting point
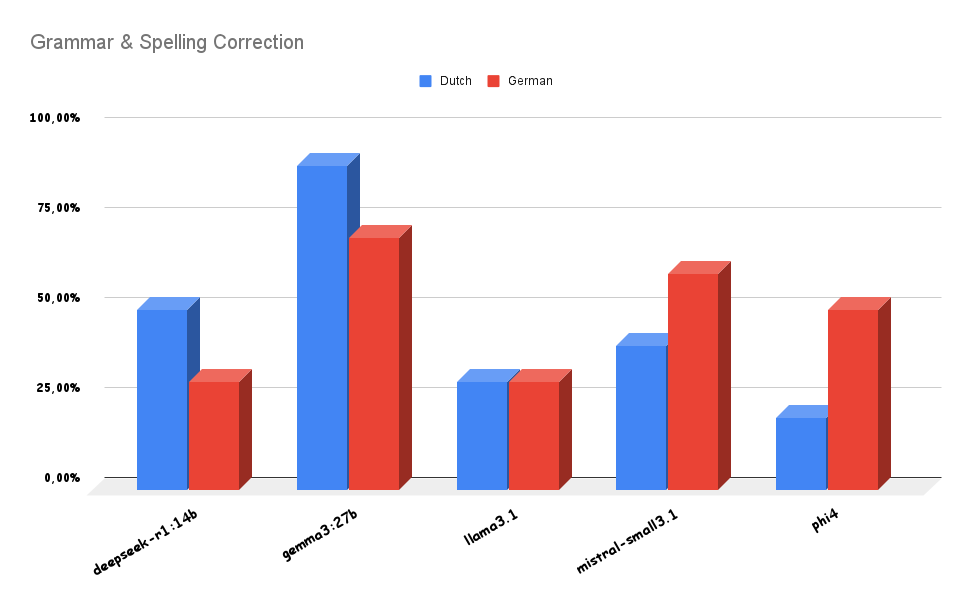
5. Task-specific performance nuance (g6.2xlarge Data) - Speed vs. accuracy:
-
- This is critical: raw speed doesn’t guarantee effectiveness.
- Gemma3:27b shows remarkable accuracy on our specific tasks (90% NL, 70% DE success on g6.2xlarge), despite not being the absolute fastest in latency or throughput. This suggests Gemma has strong capabilities for specific, potentially nuanced language tasks.
- Conversely, the faster models like llama3.1 (30% NL/DE) and phi4 (20% NL, 50% DE) perform poorly on these specific Dutch and German correction tasks.
- This highlights a crucial trade-off! You might need to choose between raw speed (Llama 3.1, Phi-4) and task-specific accuracy (Gemma 3), especially for multilingual or complex educational tasks.
EdTech use cases: Matching the right engine to the job
Based on our findings, emphasizing the G6 (L4) advantage and cost factors:
-
- Real-time tutoring / AI teaching assistants:
- Priority: Lowest latency.
- Top Models: llama3.1, phi4.
- Recommendations:
- Real-time tutoring / AI teaching assistants:
-
-
-
-
- Start with the cost-effective g6.2xlarge. If handling many simultaneous users requires more power, consider g6.4xlarge.
-
-
-
-
- Content generation (Lessons, quizzes, summaries):
- Priority: Highest throughput.
- Top Model: llama3.1.
- Recommendations:
- Content generation (Lessons, quizzes, summaries):
-
-
-
-
- g6.2xlarge or g6.4xlarge provide excellent throughput for llama3.1 on efficient L4 GPUs.
-
-
-
-
- Automated feedback & grading:
- Priority: Balance of speed and task accuracy/nuance.
- Considerations: llama3.1/phi4 are fast but struggled with NL/DE tasks. On the other hand, Gemma3:27b shows superior accuracy on these tasks.
- Recommendations:
- Automated feedback & grading:
-
-
-
-
- Simple, speed-focused feedback: llama3.1 or phi4 on g6.2xlarge / g6.4xlarge.
- Crucial accuracy (nuanced grading, specific languages like Dutch): Strongly consider gemma3:27b on g6.2xlarge / g6.4xlarge, accepting slightly lower speed for higher quality results. Thorough testing on your specific criteria is vital.
-
-
-
-
- Personalized learning path suggestions:
- Priority: Depends (real-time vs. batch).
- Recommendations:
- Personalized learning path suggestions:
-
-
-
-
- Dynamic paths favor low-latency llama3.1/phi4. Batch generation favors high-throughput llama3.1. Start with g6.2xlarge or g6.4xlarge.
-
-
-
-
- Budget-conscious startups / Pilot projects:
- Priority: Best Value (Performance per Dollar/Euro).
- Top Instance: The g6.2xlarge offers the best starting value on modern L4 GPUs.
- Recommended Models on g6.2xlarge:
- Budget-conscious startups / Pilot projects:
-
-
-
-
- Speed/Throughput: llama3.1.
- Latency/Throughput Balance: phi4.
- Task Accuracy Focus (e.g., Dutch language): gemma3:27b (accepting performance trade-off).
-
-
-
Important Note: These recommendations stem from our specific benchmarks. Always perform your testing using workloads that mirror your actual EdTech application to confirm the best fit.
Conclusion: Strategic choices for EdTech on AWS
Leveraging open-source LLMs on AWS G6 instances offers EdTech innovators powerful, customizable, and potentially cost-effective AI solutions. Our benchmarks highlight clear advantages and crucial trade-offs:
-
- G6 Instances (L4 GPUs) deliver superior performance & value: The newer L4 GPUs in G6 instances significantly outperform the older T4 GPUs (G4dn) for LLM inference, offering better speed and cost-efficiency.
- g6.2xlarge is the cost-efficient starting point: This instance emerges as the high-value “sweet spot,” ideal for budget-conscious deployments or initial self-hosting efforts, balancing strong performance with lower cost (~$880/month).
- Scale intelligently: Larger instances (g6.4xlarge, g6.12xlarge) are available but significantly increase costs. Reserve them for proven needs like handling high parallel user loads or running particularly demanding models.
- Model strengths vary – Speed vs. accuracy:
- llama3.1 and phi4 excel in raw speed (latency & throughput).
- Gemma3:27b demonstrates superior task-specific accuracy (e.g., 90% success on Dutch tasks on g6.2xlarge), making it a strong contender when correctness in specific languages or nuanced tasks is paramount.
- Speed isn’t everything: High throughput/low latency doesn’t guarantee success on specific educational tasks or languages, demanding careful evaluation beyond raw performance metrics.
Strategic advice for EdTech implementation:
-
- Prioritize G6 instances: Leverage the superior performance and value of the L4 GPUs in the G6 family for your LLM deployments.
- Align choice with need: Match the model (speed vs. accuracy) and instance size (cost vs. concurrency needs) to your primary application requirement. For Dutch language accuracy, gemma3:27b warrants strong consideration based on our findings.
- Start smart (g6.2xlarge), scale smart: Begin with a cost-effective instance like g6.2xlarge. Test thoroughly under realistic load before scaling up to more expensive instances like g6.4xlarge or larger, only when demonstrably necessary for parallelism or specific model demands.
- Test rigorously: Generic benchmarks guide, but critical testing with your specific EdTech content, tasks, and target languages (e.g., Dutch) is essential.
- Factor total cost: Remember that infrastructure (AWS costs for G6), development time, and expertise are required beyond the “free” open-source software.
- Prioritize Responsible AI: Adhere to ethical guidelines, data privacy (GDPR), fairness, bias mitigation, and robust safety guardrails.
EdTech companies can harness the power of open-source LLMs on AWS to build truly innovative and effective learning tools by making strategic, data-informed choices such as:
-
- Starting with efficient G6 instances like g6.2xlarge, which offer a strong balance of cost and performance,
- Carefully weighing the trade-off between speed and accuracy — for example, LLaMA 3.1 excels in speed, while Gemma 3 offers higher task-specific accuracy,
- Scaling thoughtfully, only when real-world performance data justifies the increased cost.

