

PostgreSQL and Indexing
Introduction
PostgreSQL is one of the most popular relational databases today. In PostgreSQL, data is stored in tables. Tables consist of columns. Each column can contain a specific type of data. Now, we will cover the basics of indexing in PostgreSQL. We will learn how indexing works. In addition, we look at when indexing should be done and how to create indexing in PostgreSQL.
Improving performance in a PostgreSQL database involves employing table indexing as an important optimization method. Also, it plays a pivotal role in swiftly locating data within a specific column. So, indexing makes queries run faster and improves database performance.
For example, in a table (sys_test) a column called “name” can contain text data. We can create our example table with the following code:
CREATE TABLE sys_test (name VARCHAR(255) NOT NULL); In PostgreSQL, tables benefit from faster and more efficient data access through indexing. An index involves creating a sorted copy of the data in a specific column of a table. For instance, when indexing the “name” column in a table, the data in that column is sorted alphabetically.
Creating Index
To create an index, we use the CREATE INDEX command. The first parameter of this command specifies the name of the index. On the other hand, the second parameter specifies the column(s) to be indexed. For example, to create an index for the “name” column in the sys_test table, we would use the following command:
CREATE TABLE sys_test (name VARCHAR(255) NOT NULL); 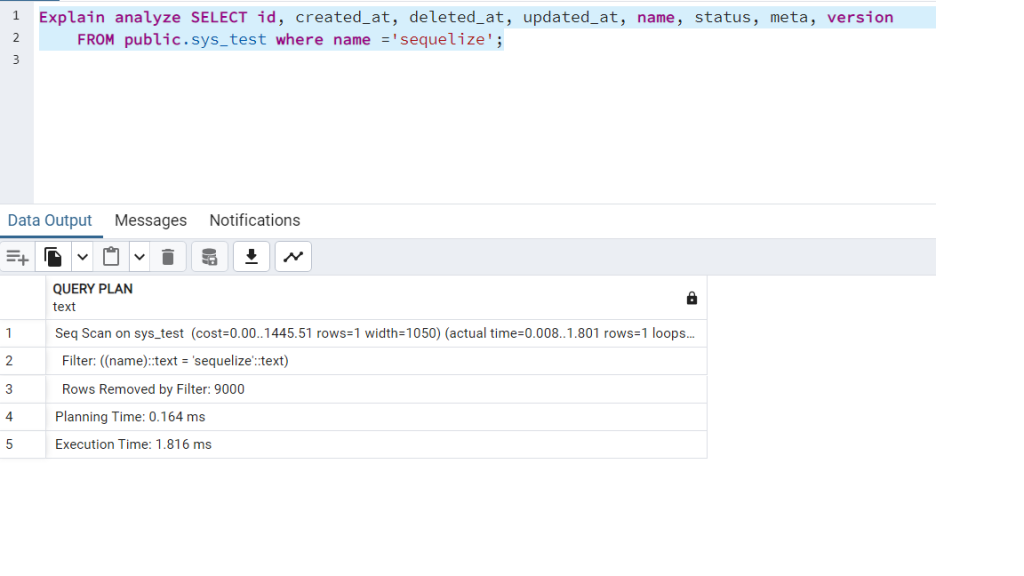
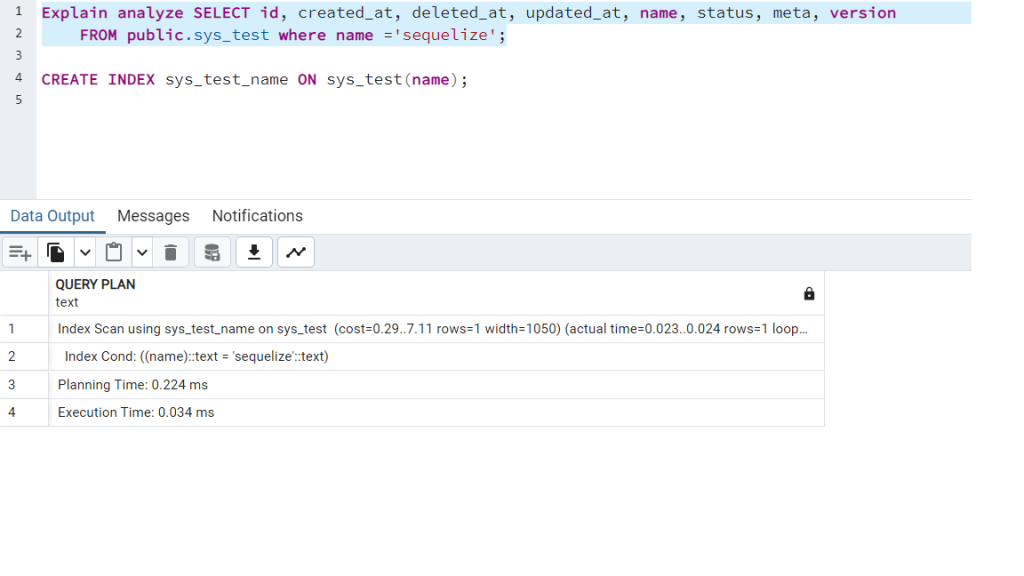
Above are two identical queries with and without index. We can see the difference between the two queries by looking at the ‘Execution time‘. The difference between these queries will not be visible. But the difference is 60 times.
1- Number of data in the table
2- Number of identical queries
3- Complexity of the query
These options will significantly impact performance, and you will notice a visible difference.
Using Index in Sequelize
Sequelize is an Object Relational Mapping (ORM) library for creating models. To create an index with Sequelize, we use the indexes parameter in create() method of the model. If you want to create an index on the “title” column in the Slide model, we use the following code. If we do not specify the type of index we will use, the type of index will be B-Tree.
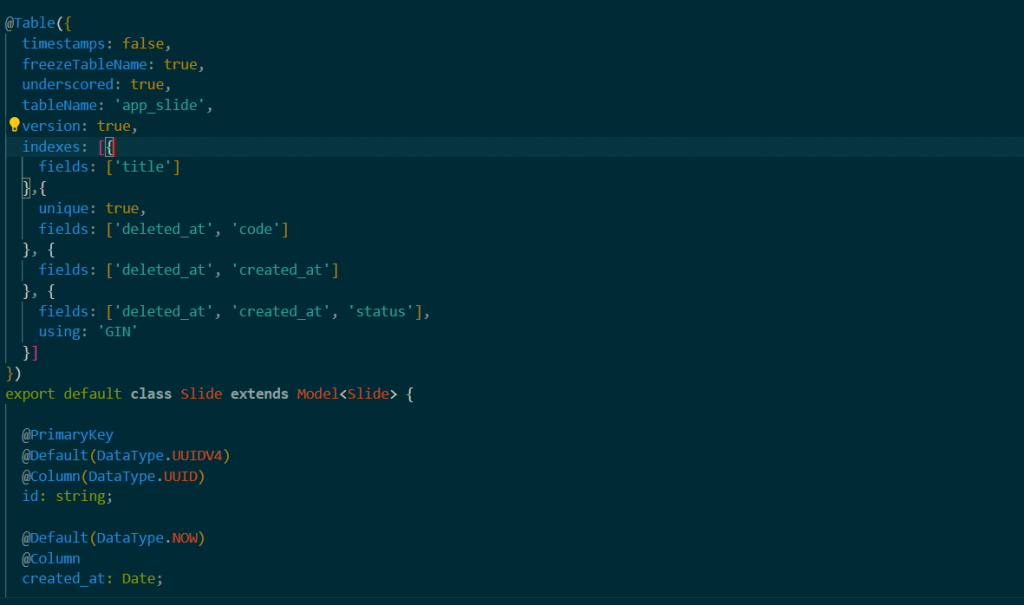
If there is more than one column in the query, we can add more than one column in the same index. In addition, we can ensure that the columns in the index are unique for the same record with the {unique: true} parameter.
For example, according to the picture 3, we will not be able to save the data with the same “deleted_at” and “code” columns in the table.
Choosing Index
When selecting an index, the most crucial consideration is aligning it with the frequency of WHERE queries. This ensures optimal performance for the table where the index will be created. For example, if we keep the user’s address information in the “address” column and we do not use it in the WHERE query, we do not need to make an index for the “address” column. The index types that PostgreSQL supports are B-TREE, HASH, GIST, GIN and BRIN. In this article we will focus on B-TREE and GIN.
If we will use the following SQL operators in the Where query, the B-TREE index will be sufficient:
=, <>, !=
<, >, <=, >=
DISTINCT, NOT DISTINCT
IS NULL, IS NOT NULL
BETWEEN ... AND If we use LIKE and ILIKE operators, B-TREE index will not work. To speed up these queries we need to use the GIN Index. The use of this is more complicated. We will focus on 2 types of scenarios. If the column type is jsonb or text, we need to consider different options.
Scenario - 1
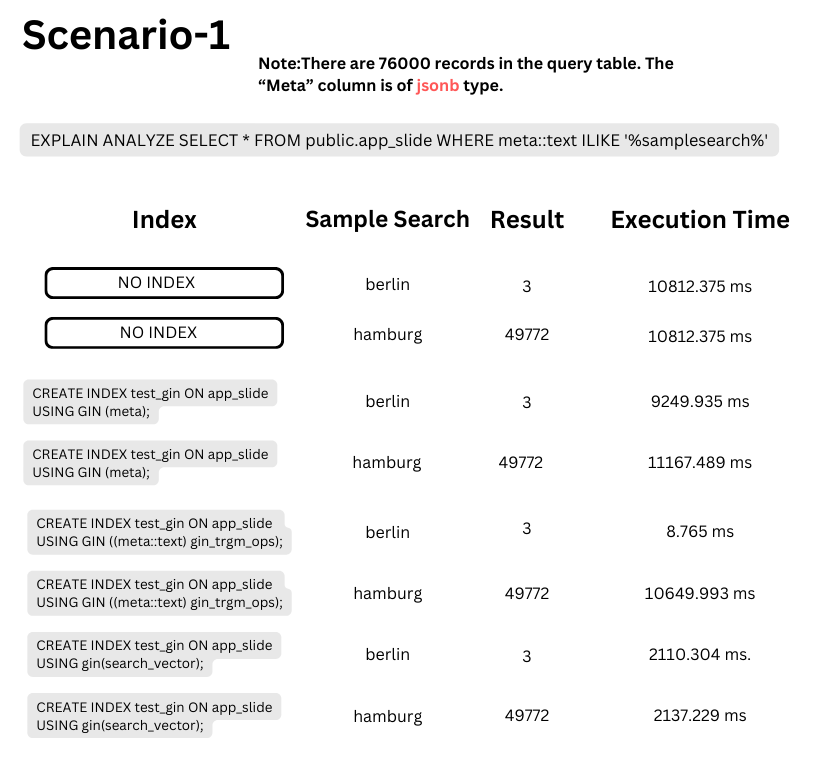
In scenario-1, directly setting up a gin index on the jsonb column showed no improvement in performance for LIKE and ILIKE queries. To address this, it’s essential to first change the jsonb type to “::text” and utilize the “gin_trgm_ops” operator to create a gin index.
When the query returns a small amount of data, the speed improves significantly—approximately 1350 times faster. However, if the majority of the table’s data is retrieved in the query, the index on the meta will still not be effective.
Another option is to use Full Text Search method. If we are going to make a lot of queries in this column and the similarity of the records is high, it can provide a lot of necessity in terms of performance. So, we need to apply the following codes step by step.
First Step
First, we add a separate column of type “ts_vector” to our table.
ALTER TABLE app_slide ADD COLUMN search_vector TSVECTOR; Second Step
We also save the column we will query (meta column) in “ts_vector” type in this column we created. When we update the “meta” column, we also need to update the “search_vector” column. So that the query result returns the correct data.
UPDATE app_slide SET search_vector = TO_TSVECTOR('simple', meta::text); Third Step
Now, we can create the index as GIN index on this newly created “search_vector” column.
CREATE INDEX test_gin ON app_slide USING gin(search_vector); If we examine scenario-1, we can see the performance increases a lot when we use a Full Text Search index. However, other indexes work much faster when the response data is few. Another important point is that in scenario-1 we always worked on “jsonb” column. This data type stores data in a table as a “(key-value)” binary and gives more freedom than other data types. If we standardize the stored data and keep it in a table, we can choose the indexes we will create more consistently. For example, in the image below, there is a data stored in the column named “meta” in “jsonb” type. Are we going to search directly on a key instead of searching the data in the object? Then, we can also create the index on this key.
CREATE INDEX test_gin_text ON app_slide USING GIN ((meta->>title) gin_trgm_ops);
{
"image": "your-url"
"title": "Mysoly Software",
"bgColor": "rgba (61, 139, 121, 1)",
"subtitle": "Have a nice trip!",
"titleSize": "h4",
"fontFamily": "roboto",
"titleColor": "yellow",
"logoDisplay": "show",
"subtitleSize": 32,
"subtitleColor": "rgba (208, 2, 27, 1)",
"titlePosition": "center",
"subtitlePosition": "center"
} In this way, we can also create a B-TREE index on standardized data (all records must have a title). However, we should have the appropriate operators in our query.
CREATE INDEX test_btree_text ON app_slide (meta->>title); Scenario - 2
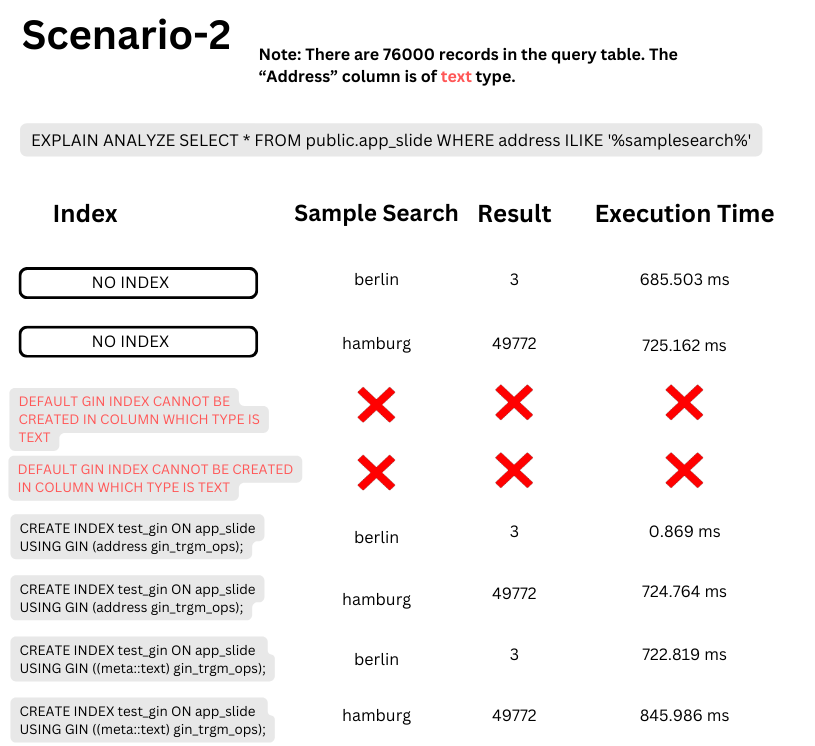
In scenario-2, we plan to use ILIKE and LIKE queries very often. So, saving this data in a separate column outside of jsonb will be very important. Because it affects the performance of our queries. Also, we cannot create the index in text-type columns.
Creating a gin index with “gin_trgm_ops” yields highly efficient results for queries with limited results. However, Full Text Search proves ineffective with low-length and simple data in the column.
Finally, the default GIN index works and is most efficient on queries of the form {“key”: “value”}. It can be used according to the need. Examples of this query type;
explain analyze SELECT * FROM app_slide WHERE meta ? 'correct'; - Searches and finds the key named correct in the “meta” column.
- Searches for and finds {“correct”: “wrong”} object and finds it.
Conclusion
As a result, indexing in PostgreSQL, when done correctly, can speed up queries. In addition, it can improve overall database performance. However, there should be care taken when choosing and using indexes.
Mysoly | Your partner in digital!

