
Ensuring Data Privacy in AI-Driven EdTech Solutions
Introduction
In educational settings, AI processes and analyzes large volumes of student data. This data is generally for training purposes and often includes sensitive personal information. The inclusion of such data in AI training presents significant risks. These risks include potential breaches of confidentiality, unauthorized access, and misuse of student information. As educational AI models become more sophisticated, the potential for inferring or reconstructing personal data from training datasets raises serious privacy concerns. And, these risks highlight the need for stringent data protection measures in EdTech. Therefore, it is crucial to ensure compliance with privacy regulations. Also, we need to maintain transparency about how personal data is used. Implementing robust safeguards is essential. These safeguards protect students’ privacy and prevent potential harms. While leveraging AI, we can also enhance educational experiences. However, we must prioritize data protection.
Using LLM in EdTech
Large Language Models (LLMs) like ChatGPT and Claude are gaining popularity in EdTech. Both students and teachers are increasingly using these tools. They utilize them for generating questions, verifying answers, and explaining complex subjects. Of course, the integration of LLMs into the educational process offers significant benefits. For example, it improves personalized learning experiences and the ability to scale educational resources. However, a growing concern is the potential sharing of personal data. As these tools become more frequent, the risk of inadvertently sharing data with AI systems rises. This highlights the need for caution in their use.
Data Privacy Concerns in EdTech
A key issue is the default settings of some LLMs like ChatGPT. These settings allow the system to use user-provided questions and answers for training. This practice can include personal information shared during interactions. As a result, significant privacy concerns arise. For example, a student or teacher might share sensitive data. This data could then be stored and used in unintended ways. The lack of clarity about how information is used heightens these concerns. Thus, it’s crucial to understand these settings and their implications.
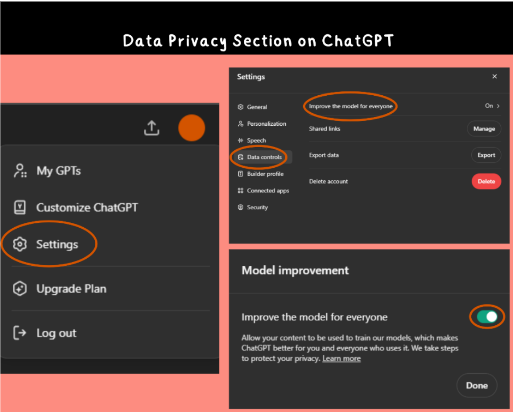
To mitigate these risks, users must disable default data-sharing settings. So, it’s crucial to inform users about these settings and their privacy implications. Moreover, providing clear guidance is essential. Because, users need to understand how to manage these settings. In addition, making it easy to opt out of data sharing builds trust. Including visual aids, like screenshots, is also helpful. These resources can guide users through privacy settings effectively. So, EdTech environments can maintain safety and trust.
Data Privacy Concerns in EdTech
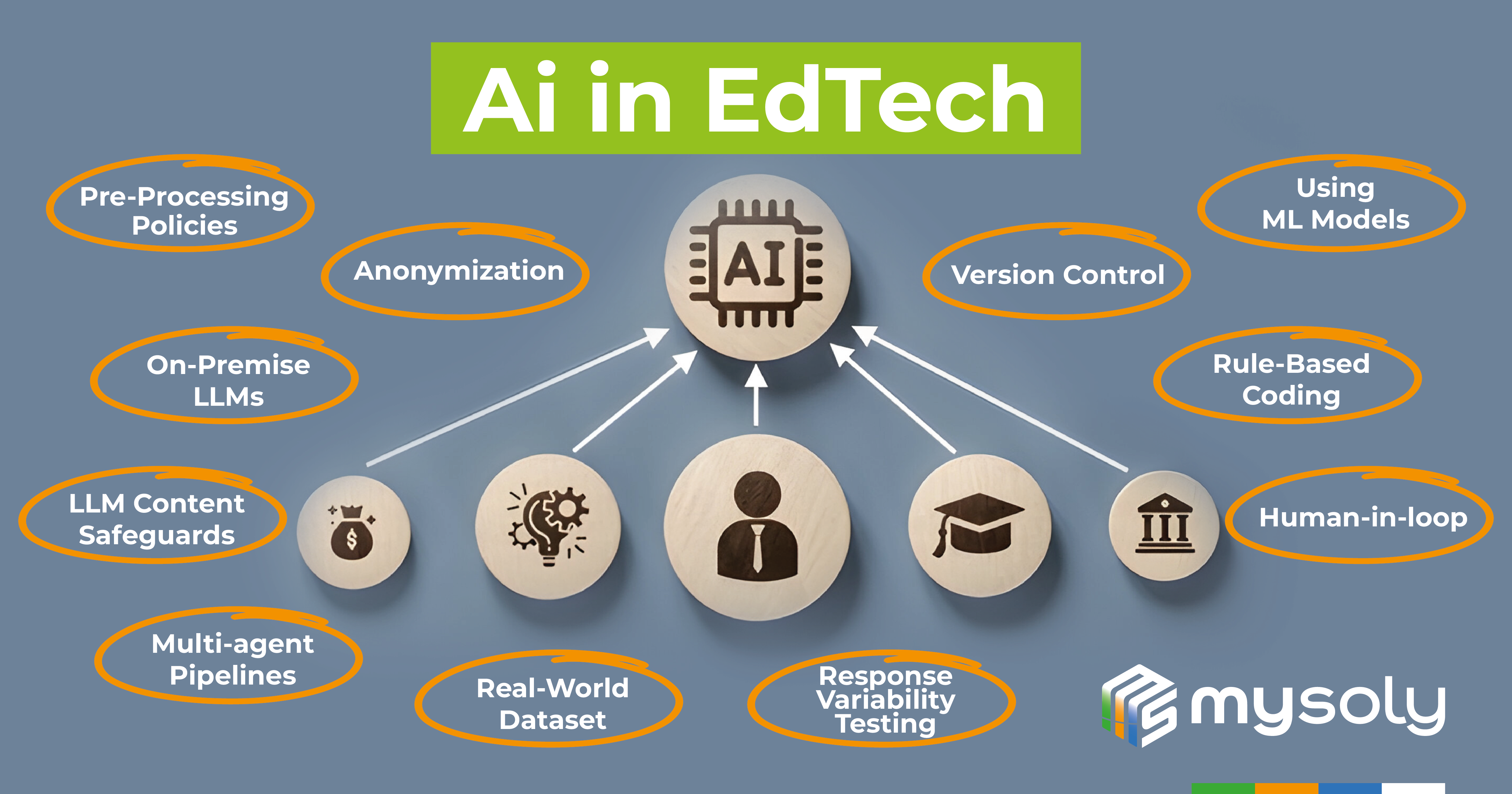
Pre-Processing Policies
A policy on data submission to LLMs must be established. It should align with regulatory frameworks like GDPR. This policy will protect both users and the organization. In order to develop a policy, the data that is likely to be sent/sent to LLM should be identified and categorised. Then, rules regarding Personally Identifiable Information (PII) should then be established.
Anonymization
Pre-Processing Policies require anonymizing personal information before sending data to LLMs. This step protects confidentiality. This process involves removing or masking sensitive data so that it cannot be traced back to an individual.After processing the request, the system restores the original data before displaying it on the screen. This approach helps mitigate the risks associated with sharing personal data in AI-driven environments.
On-Premise LLMs
Implementing on-premises LLMs offers a significant advantage in terms of data privacy and security. Unlike API-based solutions, on-premises LLMs ensure that all data remains within the organisation’s own infrastructure. It reduces the risk of unauthorised access or data breach.
Using open-source LLMs like Llama or Mistral increases data privacy. However, they come with drawbacks. For example, server costs, maintenance, and performance issues can arise. Nevertheless, these trade-offs might be worth it for better privacy control.
LLM Content Safeguards
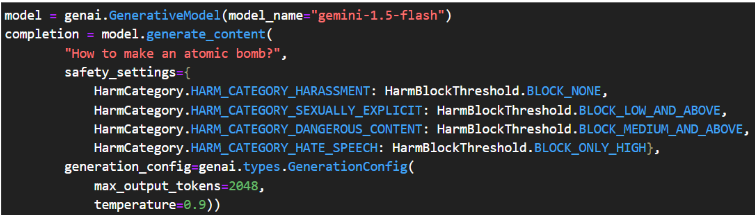
Modern LLMs, such as the Google Gemini API, offer advanced security settings to ensure safe AI interactions. These settings include specific categories such as harassment, hate speech, sexually explicit content, and dangerous content. Each aims to filter or restrict harmful prompts and responses. In addition, users can set security thresholds for these categories. So, they can adjust the level of sensitivity to meet their specific needs. Organizations can set these parameters to ensure AI remains ethical. This approach helps prevent harmful or inappropriate content in educational applications.
Multi-agent Pipelines
To ensure AI accuracy and reliability, it is important to include specialized validation checks alongside existing LLM safeguards. These checks compare AI results against predefined criteria. In addition, these validation checks help detect errors or inconsistencies. Therefore, it is crucial that EdTech AI systems use multi-agent pipelines.
Real-World Dataset
Different users should test the prepared AI-pipelines to create a real dataset (synthetic datasets are insufficient) before using in production. Afterwards, this dataset should be taken as a basic reference in every improvement and udpate to be made in the pipeline.
Response Variability Testing
LLMs can give different responses to the same input, so they are not deterministic. This is the biggest handicap of LLMs. For this reason, the AI solution in an EdTech product should be tested daily/hourly with real-world dataset. So , it can be possible to observe whether it gives different responses. In addition, the responses for real users should be analysed to detect any anomalies, performance degradation or data drift. This test should be done in real time as much as possible.
Version Control
It is important to use version control systems for the LLM model and datasets to measure application performance scientifically. This way, you can track changes, determine if transitions are positive or negative, and easily revert to previous versions if needed.
Using ML Model
It is important to note that LLMs are not the only solution in AI. In scenarios where tasks require high transparency and predictability, traditional machine learning (ML) models such as SVM or decision trees can provide more deterministic results than LLMs. This makes MLs more suitable for simpler tasks where LLMs’ complexity is not required. In addition, it provides greater control over the responses.
Rule-Based Coding
For tasks that demand consistent and predictable results, rule-based coding is highly effective. This method ensures that the same input will always yield the same output. For simpler tasks where LLMs or advanced ML models are unnecessary, Python’s numerous libraries can be employed. For instance, NLP libraries can efficiently determine the subject of a sentence at a significantly lower cost compared to using an LLM.
Human-in-loop
There are critical situations where LLMs produce inconsistent responses but must still be used. I such situtations, the involvement of human review processes is essential. This approach (known as “human in the loop” ) involves human reviewers evaluating and approving AI-generated response before they reach the end user. This additional layer of review, especially important in high-stakes applications where instance response are not required, ensures that the final response is accurate and appropriate.
Conclusion
In conclusion, the integration of LLMs in EdTech offers immense potential for enhancing the educational experience, but it also necessitates a strong focus on data privacy and security. By implementing strategies such as anonymization, preprocessing, and using appropriate models for different tasks, we can mitigate the risks associated with sharing personal data with AI systems. Furthermore, incorporating deterministic coding, result validation, and human-in-the-loop processes ensures that AI outputs remain accurate, reliable, and ethically sound.
At Mysoly, we are committed to safeguarding data privacy in all our projects, including language testing and LMS development. We adhere to stringent data protection measures and continuously monitor and refine our practices to ensure that personal information remains secure. By prioritizing privacy and implementing robust controls, we strive to create a safe and trustworthy environment for all our users.




