

Speech-to-Text with Faster-Whisper: The High-Speed Alternative to OpenAI Whisper
Introduction
Open AI Whisper is an AI model that converts spoken language to text. Whisper is trained with multilingual and multitask data collected from the web. Whisper is resilient to accents, background noise, and technical language. The first version of the Faster-whisper was released in November 2023. It is a reimplementation of the OpenAI Whisper model using CTranslate2. CTranslate2 is a fast inference engine for Transformer models.
Faster-whisper is up to 4 times faster than openai-whisper for the same accuracy and uses less memory. For faster whisper modeling work, it offers 2 options as “CPU” and “GPU”.
This article focuses on CPU-related aspects of Faster-Whisper. It covers crucial model parameters, introduces Real-Time Factor (RTF) for speed comparison. Also, it guides readers on transitioning from OpenAI-API to Faster-Whisper, including AWS server compatibility.
About Faster-Whisper
Faster-whisper, unlike OpenAI-API, offers parameters that you can change according to your needs. The first important parameter is model_size. There are different sizes such as base, tiny, small, medium, and large. As the sizes change in order, the accuracy score increases while the working speed also increases.
One of the other important parameters is beam size. It controls the number of paths at each step when creating the output. For example, when beam_size is 5, the model chooses from the best 5 possible paths at each step. The value of beam-size affects the balance between the accuracy and speed of the analysis. A larger beam-size value provides a more accurate analysis but increases the computation time.
Real Time Factor (RTF)
There are many metrics to measure the efficiency of the classification model in machine learning. These are precision, recall, accuracy, f1 score, confusion matrix. However, it is not appropriate to use such metrics directly in the evaluation of voice models. Real time factor (RTF) is a metric that measures the speed of the speech recognition system in speech recognition. Real time factor is the processing time divided by the duration of the voice input. The smaller the real time factor, the faster and more real-time the system is.
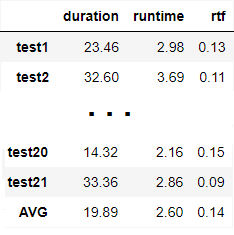
The RTF value of the OpenAI Whisper API is 0.14.
Word Error Rate (WER)
RTF is pretty straightforward, but is it enough to evaluate a model on its own? For example, does the fact that a model with a low accuracy rate (success rate in speech-to-text) has an acceptable RTF value mean that we should accept the model as successful?
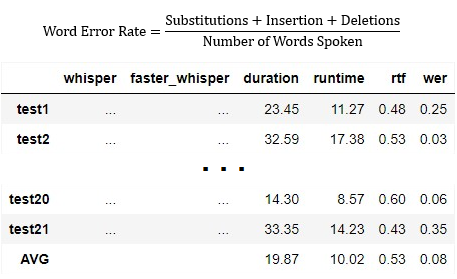
Therefore, the word error rate (WER), the error rate between the text by the model and the actual text, is an important metric. This metric together with RTF will allow us to comment on the accuracy of the model.
How can we measure the WER for accuracy of the result? WER is derived from the Levenshtein distance, working at the word level instead of the phoneme level. The general difficulty of measuring performance lies in the fact that the recognized word sequence can have a different length from the reference word sequence (supposedly the correct one).
To calculate the WER, you need to consider three types of errors:
- Substitutions: When a word gets replaced. For example, “twinkle” is transcribed as “crinkle”.
- Insertions: When a word gets added that wasn’t said. For example, “trailblazers” becomes “tray all blazers”.
- Deletions: When a word is omitted from the transcript. For example, “get it done” becomes “get done”.
The formula to calculate Word Error Rate is:
Evaluation Method
We’ll compare Faster Whisper with OpenAI Whisper API by calculating RTF on Dutch test data. To generate the RTF, we need to get the duration of each audio file in the test data. Then, we also need the response time of the Faster Whisper model we used. We divide the response times by the normal duration of the audio. So, we can get the RTF scores for each audio file. In the table above, we can see the RTF value to approach in terms of speed is 0.14. Therefore, we will compare the RTF scores of the model with faster-whisper with 0.14.
At the same time, we will also consider the WER values close to 0.0
Faster-Whisper on AWS Server
We tried the faster-whisper model with different parameters on AWS. Let’s compare the model size and beam size. They are important parameters that affect the accuracy and speed.
If we interpret the small models with different beam sizes, as you can see, as the beam size increases, the error rate of the model decrease while the RTF score also increases. The increase in beam size makes small improvements in the score, but here you have to make a decision between speed/accuracy according to your business needs. Looking at the medium model again, firstly, since the model_size increases, the RTF increases, but the error rate shows a more serious decrease. On the other hand, the score does not improve excessively against different beam sizes, so the optimal beam_size can be said to be 1 in the medium model.
Results In Different Instances
What would be the cost and performance of this if we try it on different AWS instances? Would it be a better decision to create our own API on a separate server? Let’s compare this on different servers.
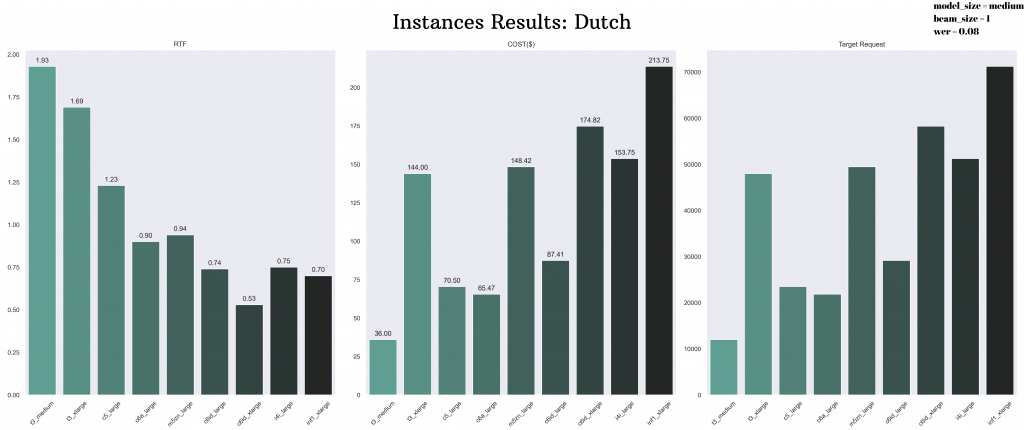
First of all, this table includes the faster-whisper’s medium, beam size 1 model, which achieved more balanced results in the Dutch language. In the table, we see the values of which AWS instance the model runs on, RTF value, and monthly cost. It also includes how many requests per month faster-whisper can offer (need_request) in the application we created. Different system requirements affect the speed and cost of the AWS instances.
Let’s explain the need request column a little more. The expected sounds have an average duration of 30 seconds. So the unit cost of this with OpenAI API is about $0.003. In the transition to the server, we found the requests that needed to be reached by multiplying the monthly costs we specified as cost by our budget and dividing it by the unit cost ($0.003) we found with OpenAI API.
For example, if we examine the c6id_xlarge instance type, the RTF value came out better than the other servers tested as 0.53. The server’s monthly cost was $174.82. Also, it was appropriate to switch if 58,275 requests were made monthly with OpenAI API.
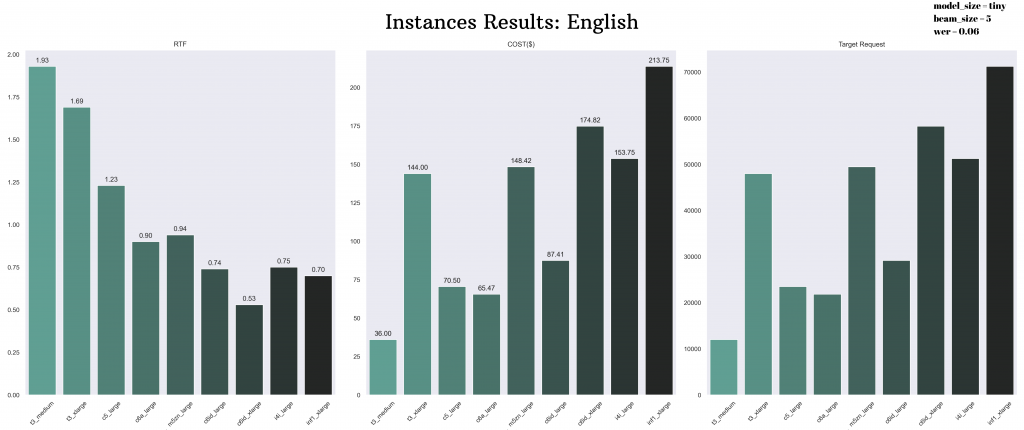
You can also examine the results with the test data of the English language from the table below.
Conclusion
In this study, we compared Faster-Whisper with the OpenAI Whisper API. After giving information about the model parameters, we discussed the working environment of the model in AWS. Especially in the prototype phase, we run the models on our local computer, but for production, we need a server. Therefore, to evaluate the performance of a model healthily, it is necessary to make a decision based on the results in the server environment.
In brief, performance comparison includes a 3-metric evaluation, including the Real Time Factor (RTF) and Word Error Rate (WER) metrics, as well as the choice of server type (and therefore cost). This is closely related to the purpose/budget of the project. We explained the importance of this comparison in detail in the study.




